System Design Basic 2 - A Single System Example
Scale From Zero To Millions of Users
A step by step example
Single server setup
-
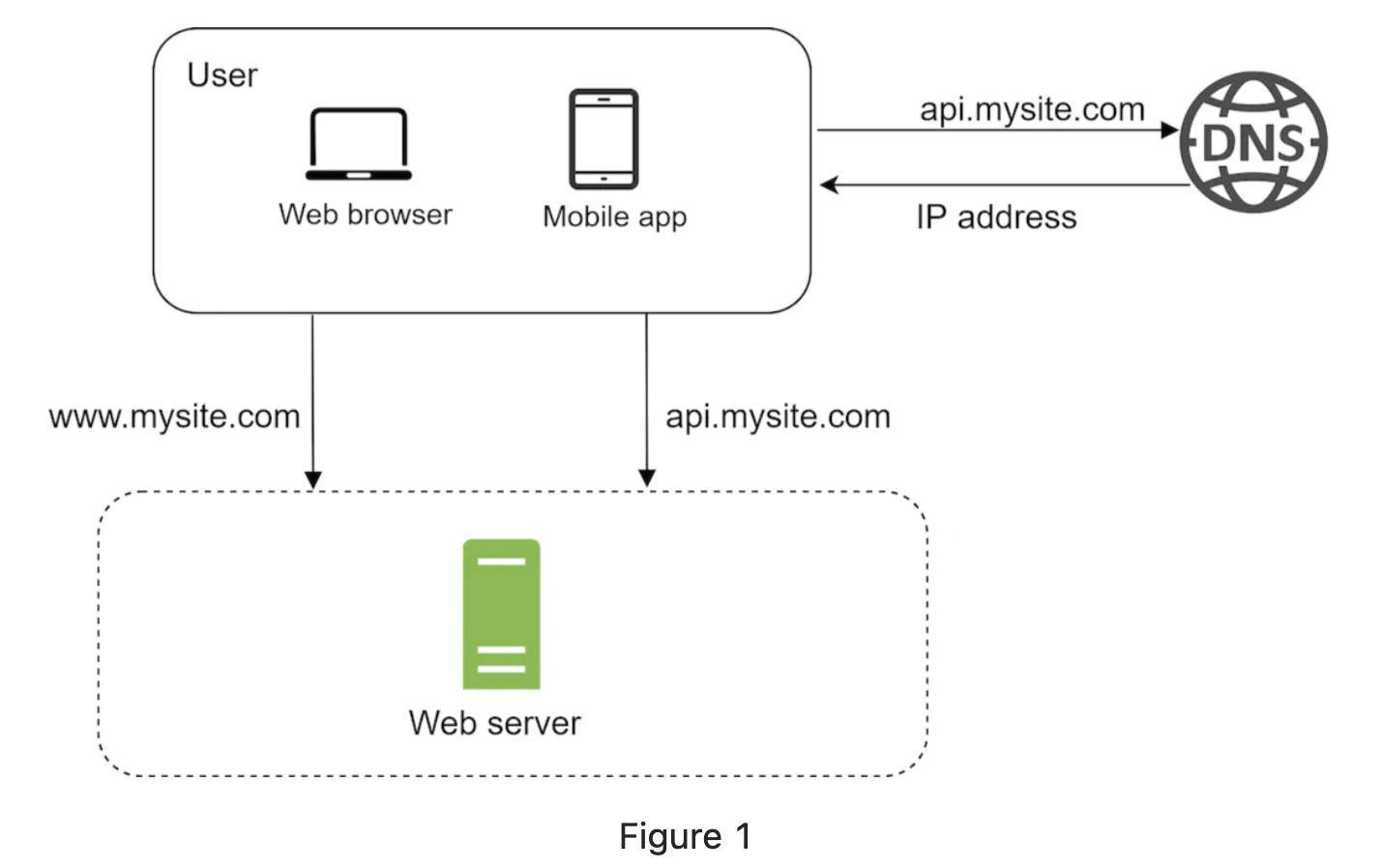
User access web throught domain names. The Domain Name System(DNS) is a paid service provided by 3rd party and not hosted by our servers.
-
Internel Protocal(IP) address is returned to browser or app.
-
Once the IP is obtained, Hypertext Tranfer Protocal(HTTP) requests are sent directly to web server.
-
The web server return HTML pages or JSON response for rendering.
-
The trafic
-
Web application. It uses a combination of server-side language(Java, Python, etc.) to handle business logic, storage, etc., and client side languages(HTML and Javascript) for presentaion.
-
Mobile Application. HTTP is the communication protocal. Javascript Object Notation (JSON) is commonly used for API response format to trasfer data due to the simplicity. A example JSON response:
GET /users/12 – Retrieve user object for id = 12
{ "id":12, "firstName":"John", "lastName":"Smith", "address":{ "streetAddress":"21 2nd Street", "city":"New York", "state":"NY", "postalCode":10021 }, "phoneNumbers":[ "212 555-1234", "646 555-4567" ] }
Database
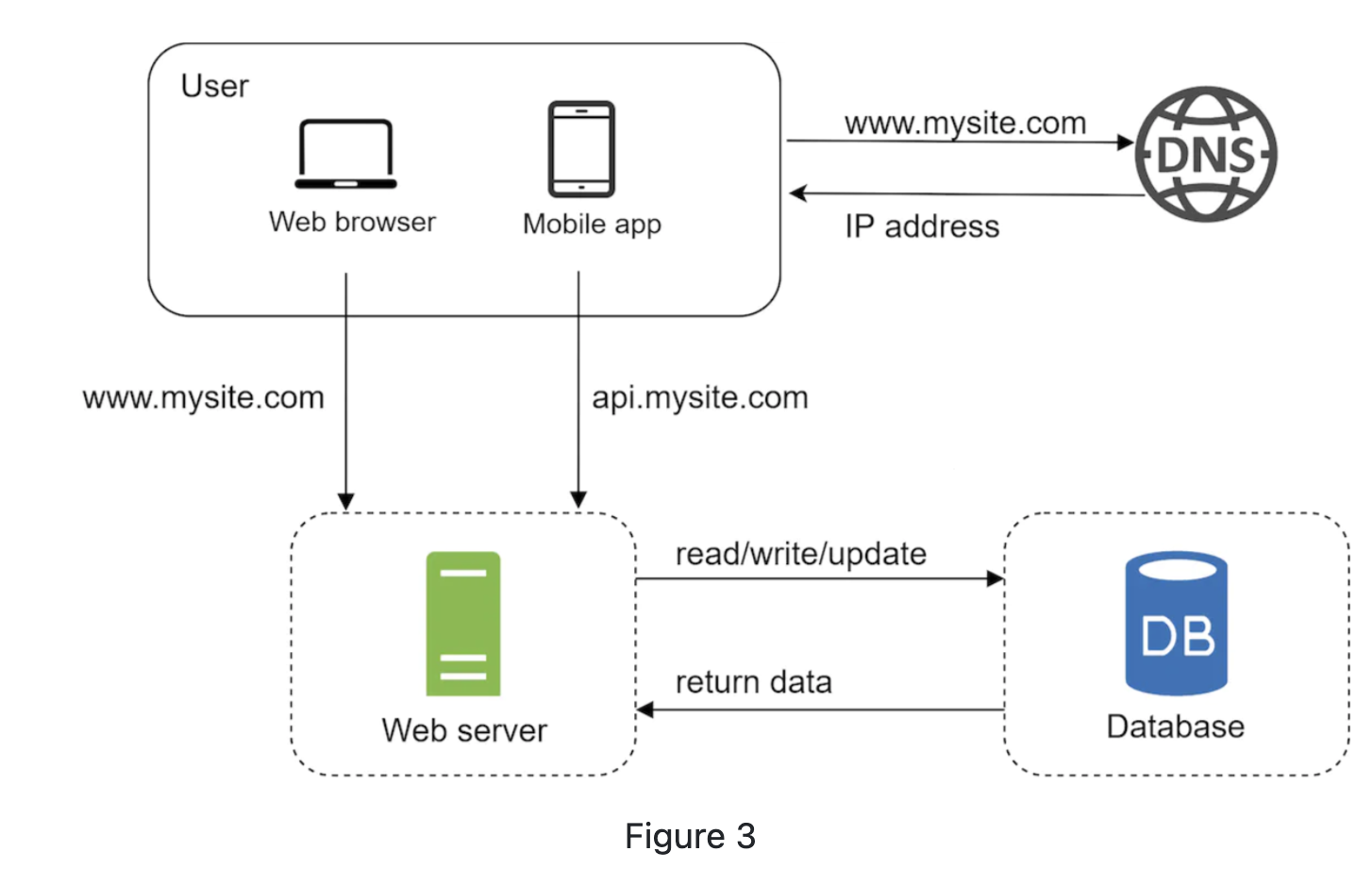
With growth of the user base, one server is not enough, we need multiple servers: one for web and the other for the database. Seperating traficts allows them to be scaled dependently.
-
Which database to use?
- Traditional relational databases
- also called relational database management system(RDBMS) or SQL database.
- Example: MySQL, Oracle database, PostgreSQL..
- represent and store data in rows and columns, You use join across tables to 'connect' data in different tables.
- Non-relational databases
- Also called NoSQL databases.
- CouchDB, Neo4J, Cassandra, Hbase, Amazon DynamoDB.
- Grouped in for categories: Key-value, graph, column, document
- Notmally do not support JOIN
- Might be right choice when:
- requires super-low latency
- unstructured data or non-relational data
- data serialization and deserialzation needed (JSON, YAML, XML,...)
- store massive amount of data..
Vertical Scaling vs horizental scaling
- Vertical scalling: scale up. means adding more power(cpu, RAM etc.) to servers.
- Advantage: simplicity
- disadvantge:1) limit: you cannot add unlimited CPU and memory 2) have no failover and redundency
- Horizontal scaling: scale out. adding more servers to pools.
- If the server is offline; or too many user access server which cause a slowdonw or fail to connection, a load balancer is the best technique.
Load Balancer
-
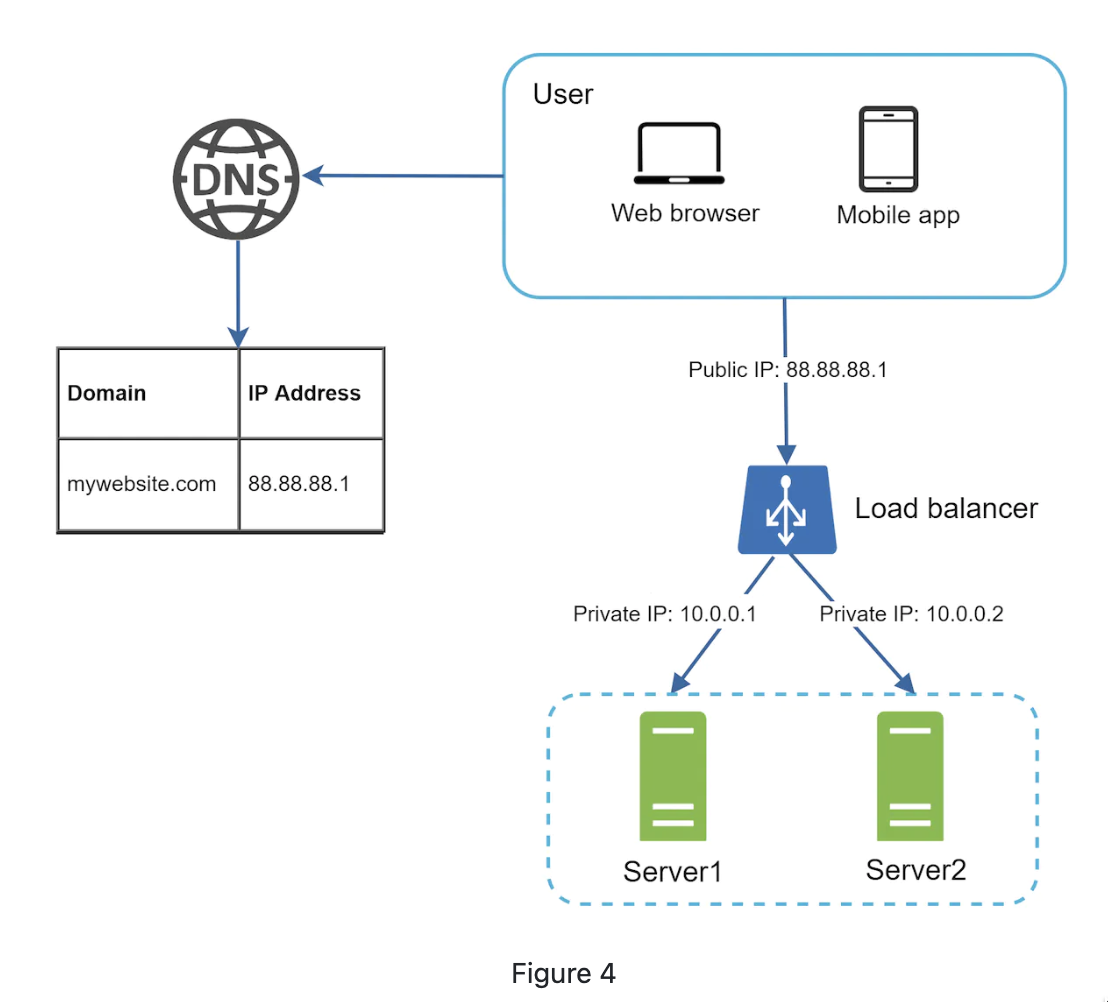
A load balancer evenly distrbuts incoming traffic among web servers.
-
Users connect to the public IP of load balancer rather than directly to the servers.
-
Load balancer communicate with web servers via private IPs.
-
Solved no failover issue and imporve availability.
The single point of database doesn't support failover and redundency.
Data Replication
-
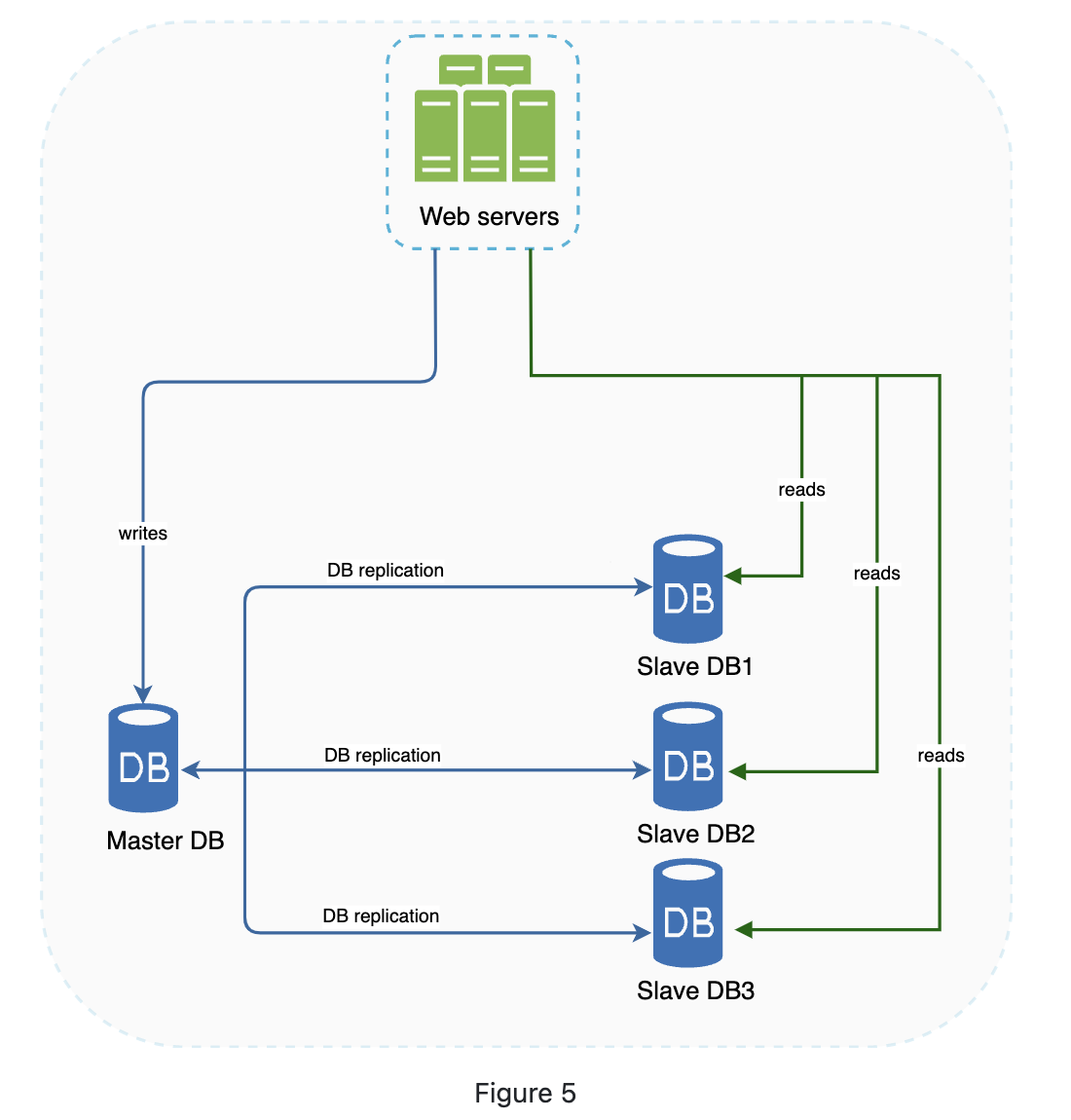
Master database: accepts write operations.
-
Slave database: accepts read operations.
-
Most applications requires a high ratio of read write so the slave is more than master in a system. (According DDIA this is only one kind of replication (Master-Slave))
-
Advantage
- Better performace: it allows more queries run in parallel;
- Reliability: If one database replocation is destroyed, others still have you data.
- High availability: if a database is offline, others are still available to support data quering.
-
How data replication improve availability?
-
if only one slave available and down, the traffic will go to master temporarily and once the issue was resolve, a new slave will repalce the old one.
-
If multiple slave available and some of them down, the read request will redirect to other healthy ones. and a new database server will replace the old one.
-
If the master goes down. A slave will be prompted to master and a new slave database server will replace the old one.
one problem is maybe the new master do not have updated data and needs to be update. This will be more complicated when doing this.
-
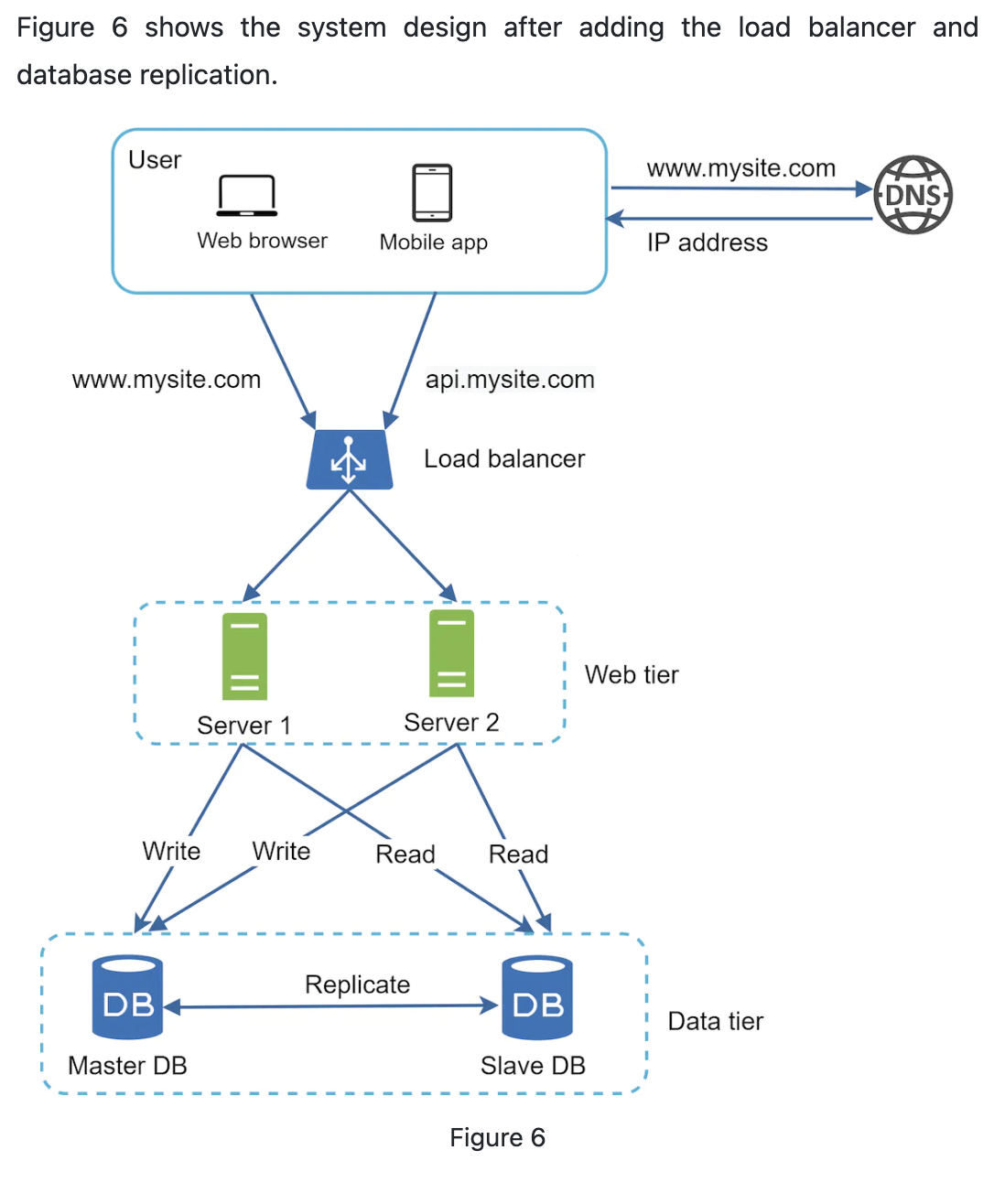
it is time to improve the load/response time. This can be done by adding a cache layer and shifting static content (JavaScript/CSS/image/video files) to the content delivery network (CDN).
Cache
- Cache: temporary storage are that stores expensive resopnses or frequently accessed data in memory so that subsequent requests are served more quickly.
Cache tier
-
Benefits: better performance, reduce database workloads, scale the cache independently.
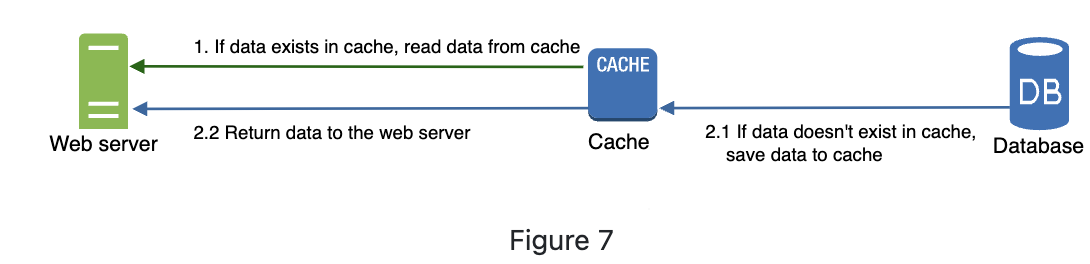
-
this Caching strategy: read-through
-
interacting with cache servers is simple because most cache servers provide APIs for common programming laguagues.
-
A typical Memchached APIs:
SECONDS = 1 cache.set('myKey, 'hi there', 3600 * SECONDS) cache.get('myKey')
Considerations for using cache
- When to use: More read, less write; not for persistance vital data.
- Expiration policy: expiration date not too soon thus cause reload data too frequently; and not to long to prevent data to be not fresh.
- Consistency:
- Mitigation failures
- a cache server represents a potential point of failure.
- multiple cache servers accross different data centers are recommended
- Or overprovison the required memory to provide buffer for memory increasing.
- Eviction policy: LRU/FIFO/LFU
Content delivery network(CDN)
- geographically distributed servers to deliver static contents(iamges, videos, CSS, javascript files.
- The further the CDN is from a client, the longer the request time it is normally.
- How does it work:
- User A visist a website, a CDN server close to it will deliver the static content.
- If the CDN server does not have the content, it will request from the orginal server, and stores in the CDN server for further use, with a expiration time(TTL-time_To_Live);
- if the server has the content, the contents would be returned directly unless they are expired.
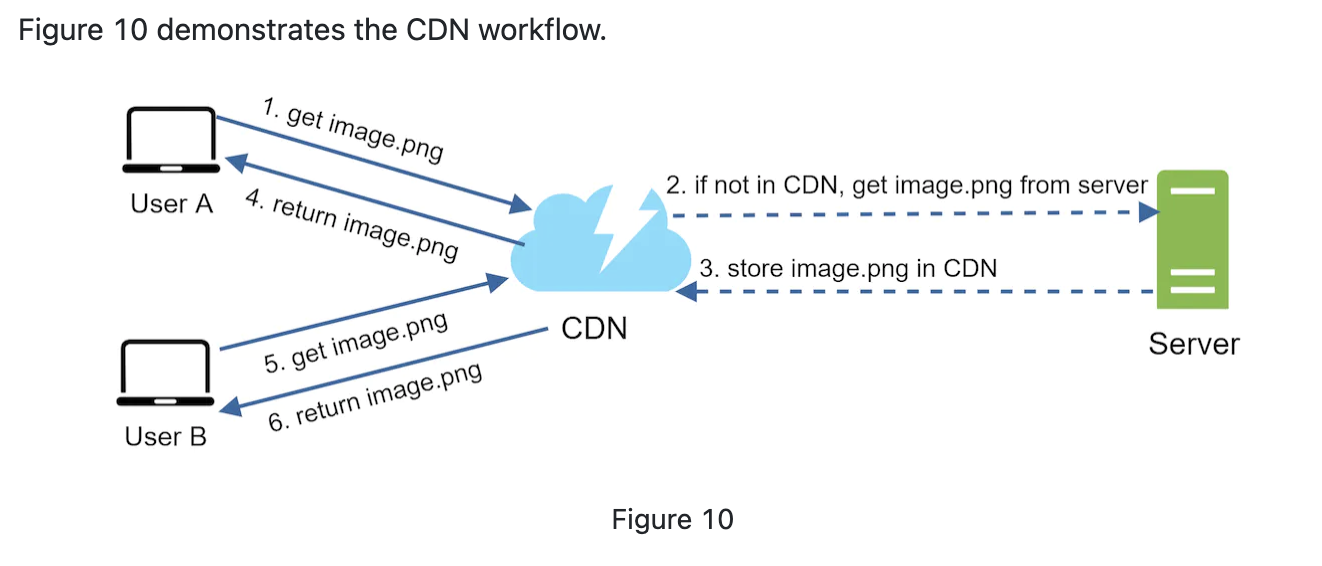
- Considerations of using CDN
- Cost: if you cache infrequenly used things, that may be worthless.
- Cache expiry: not to long, not too short.
- fallback: how to handle CDN down.
- Invalidate the CDN objects:
- via API provided by vendors
- via a versioning server to version things and you fetch the latest version each time.
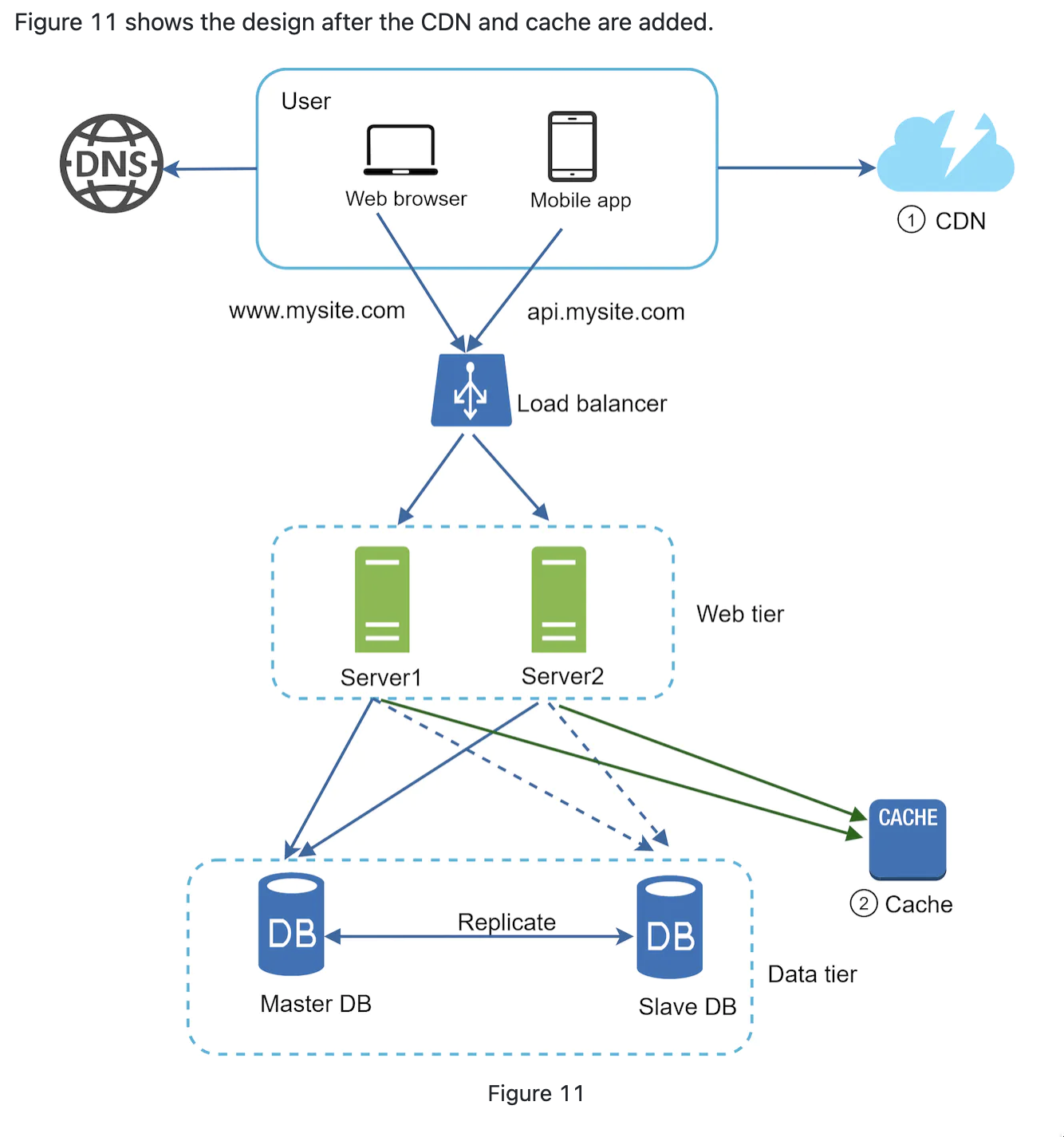
- better perfomance for retriving static contents; less pressure on database by caching data.
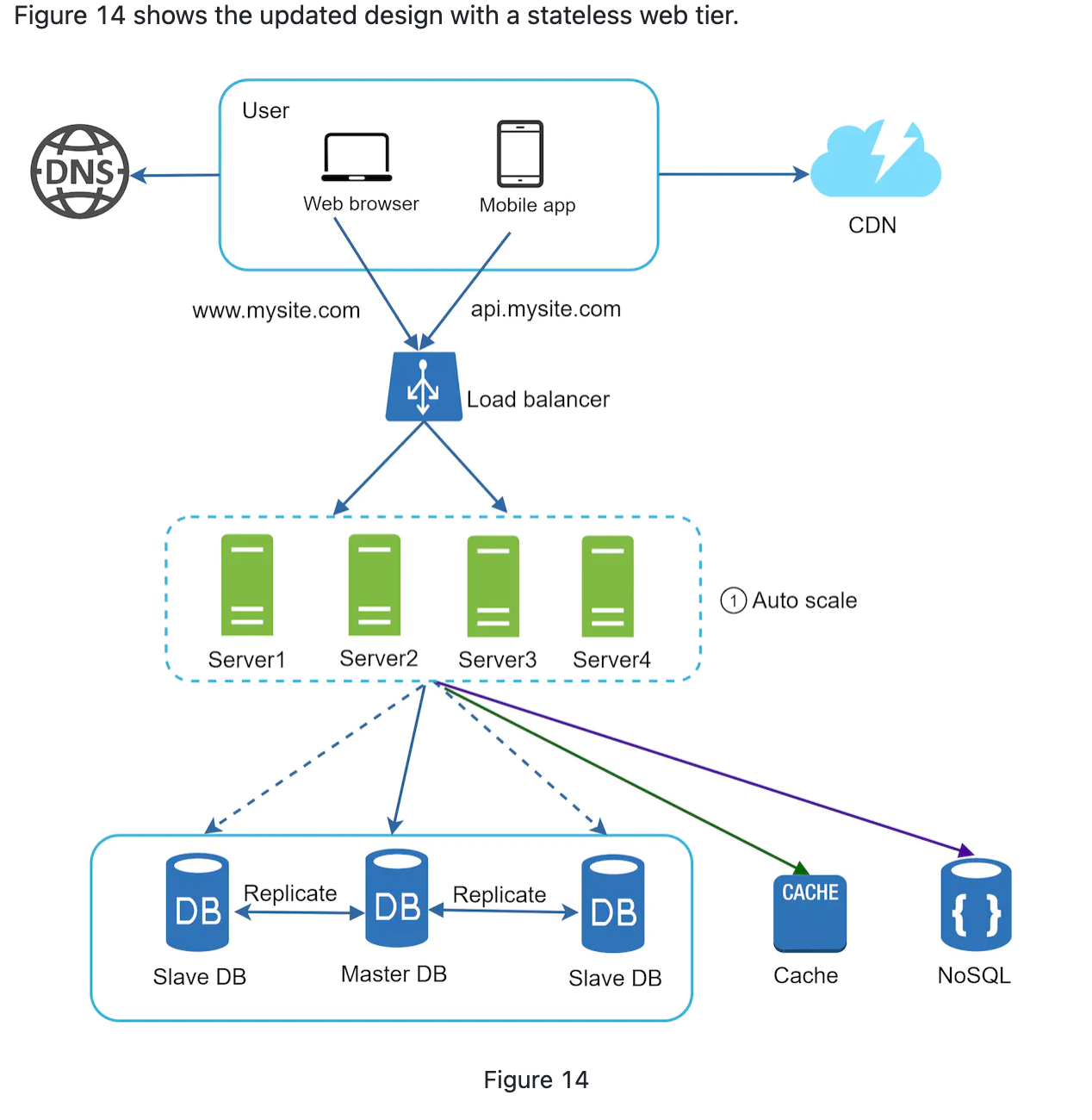
Stateless web tier
It's time to scale up.
Stateful data: user session data, etc.
We need to move these data out of single server and store them into persistence storage. So each server can access them. This is called stateless web tier.
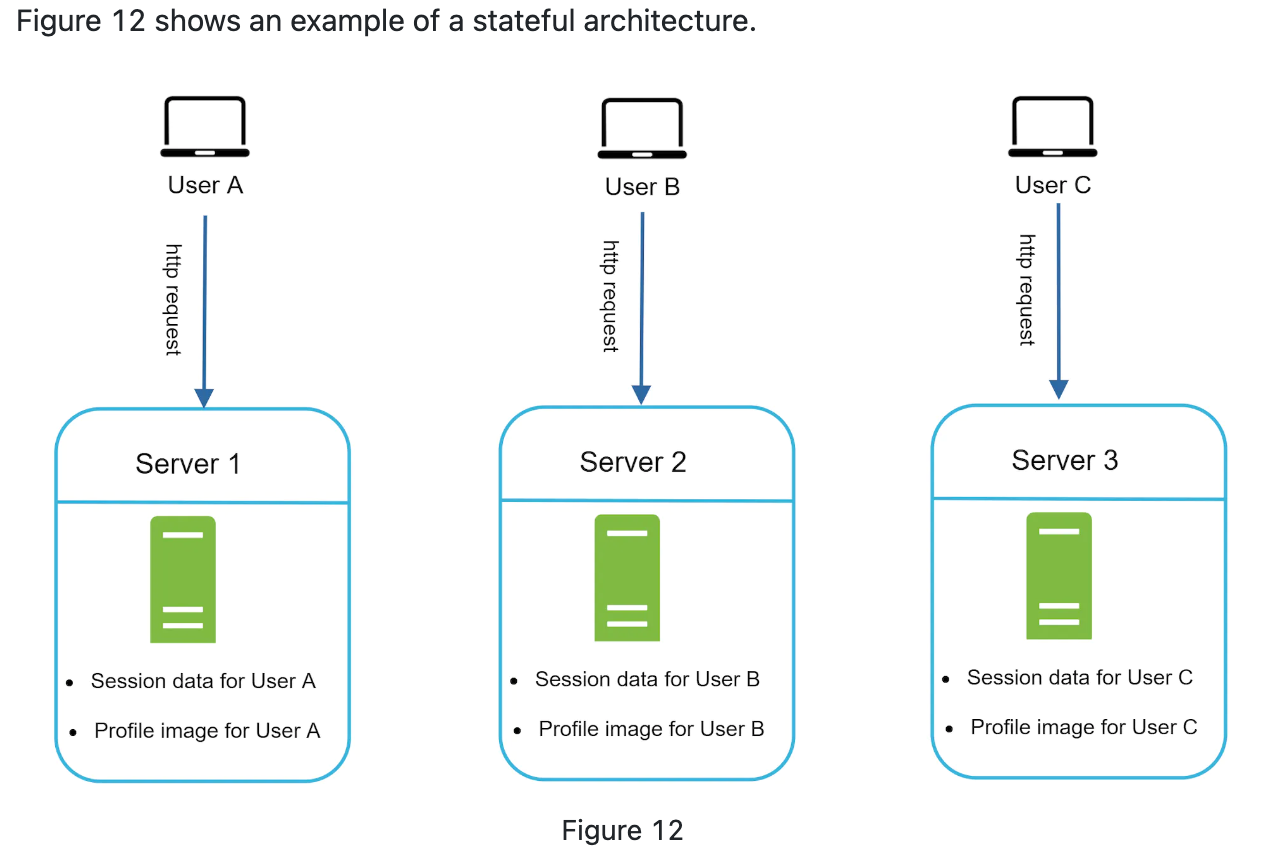
Stateful architecture
-
stateful server vs stageless server
-
The issue is that every request from the same client must route to the same server. This can be done in load balance but added overheads.
-
Adding or removing(or server fail) is more difficut.
Stateless architecture
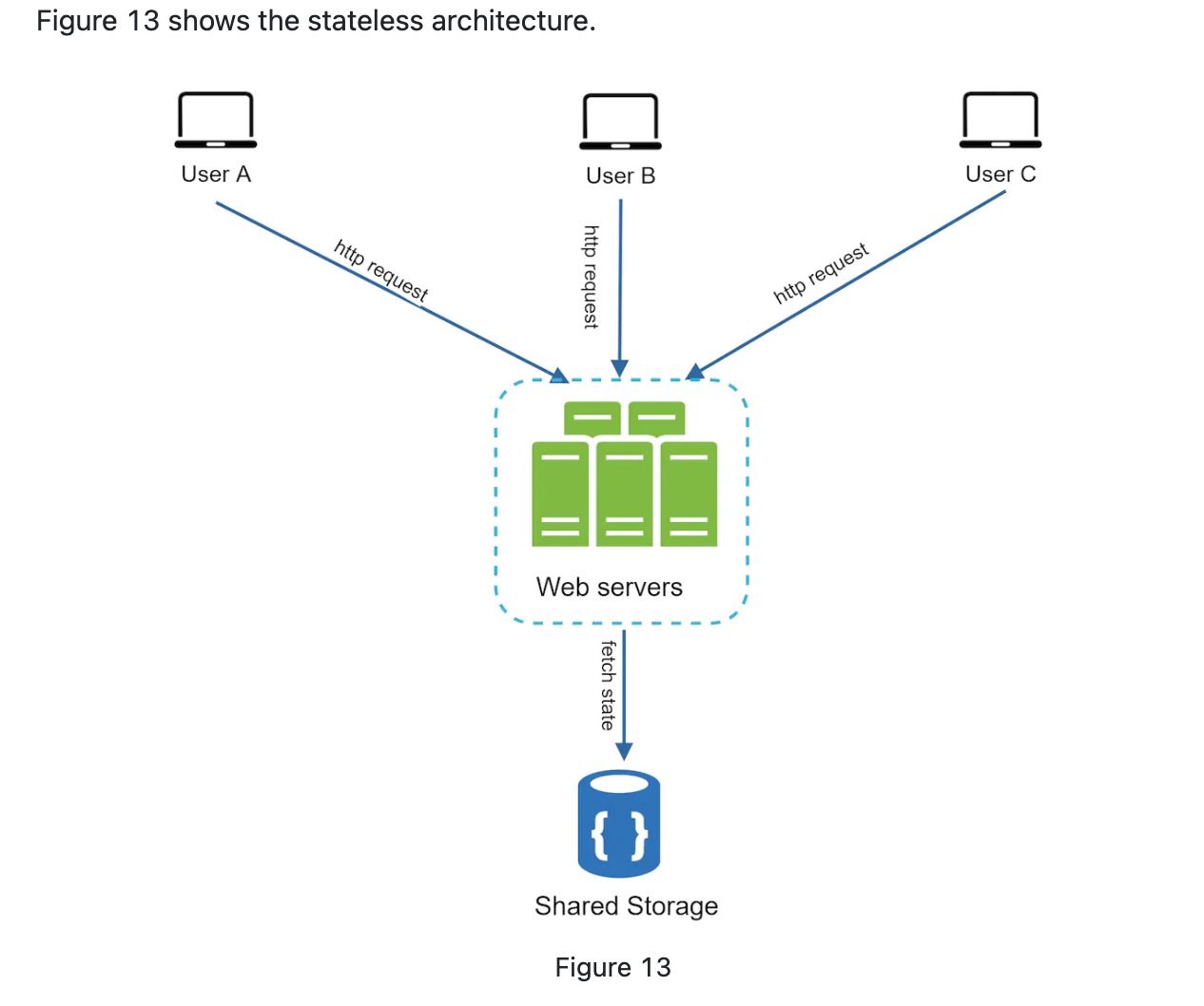
- Auto scaling(add or remove server based on trafic load) is easy by moving out state data from server.
Data centers
- we could use geoDNS (provided by DNS service) to route to closest data center.
- geoDNS, also know as geo-routed, allows domain names to be resolved to IP address based on the location of a user.
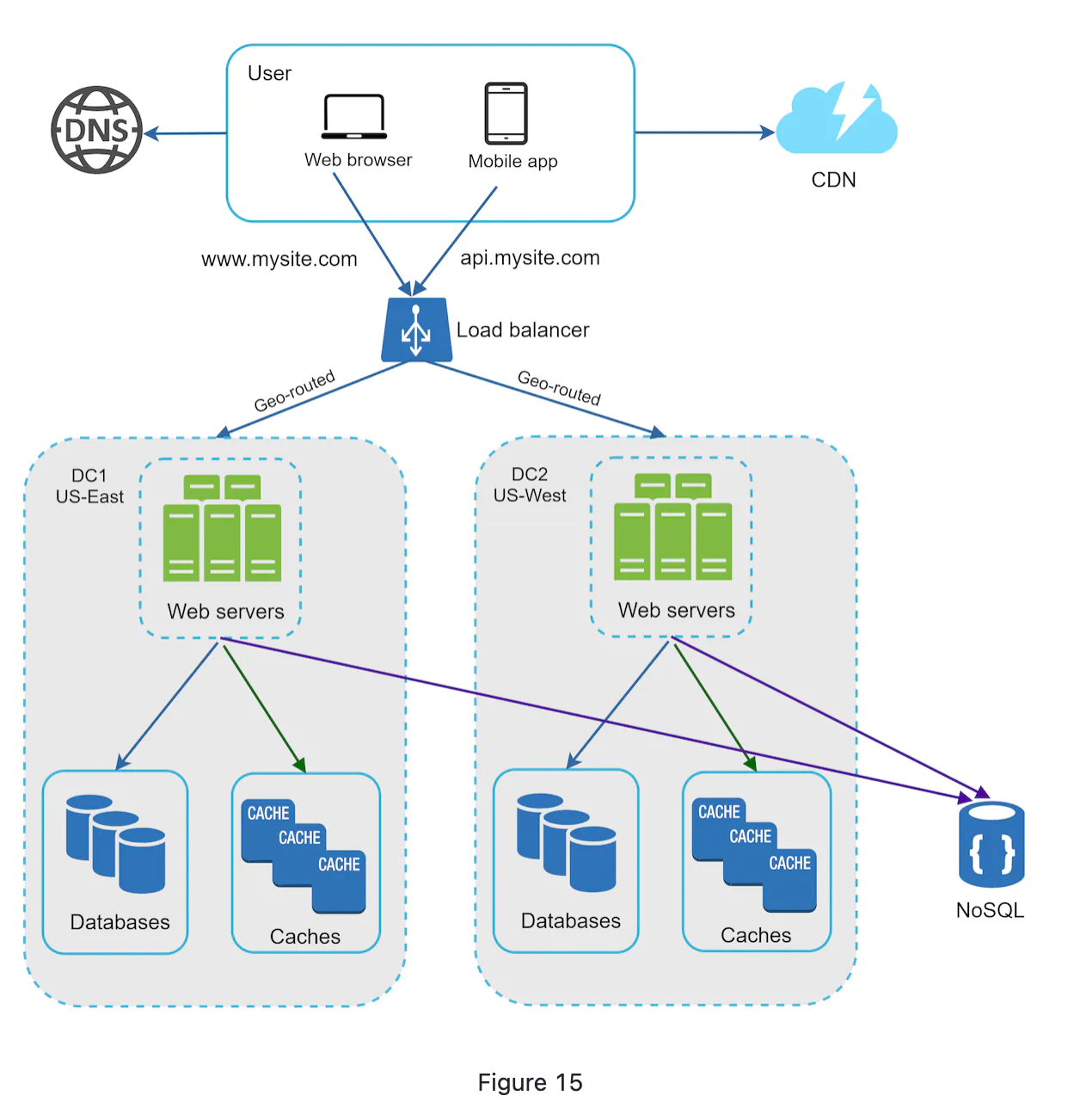
- If one data center ourage, the trafict will be routed to a healthy one.
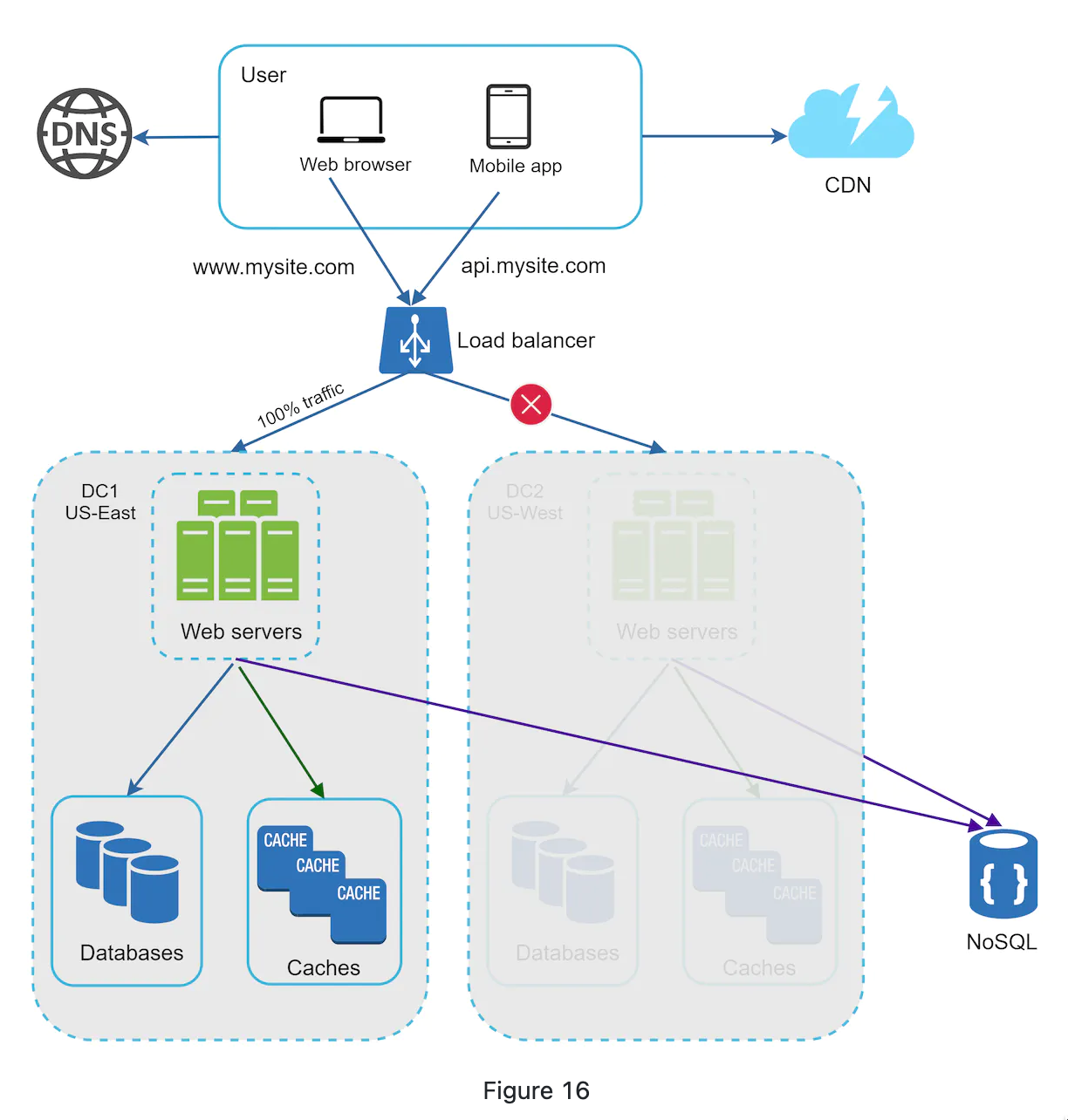
- Techinical challenges for achiving multi-data center
- traffic redirection
- data synchronozation
- Test in diffrent locations to make sure they are good
- Auto delopyment tool is vital for consistent data in all data centers.
To further scale, we need to decouple components to allow them scale independently. Messaging queue is a key stretegy to solve this.
Message queue
-
a message queue is a component that supppots asynchronose communication bewteen components of a systme and can be either stored in memory or on disk to achive durability.
-
The architectur

-
Decoupling makes it a prefered arechtecture for scaling system.
-
The producer and consumer can scale or shirink based on the workload.
Logging, Metrics, automation
-
Logging
-
Metrics
- host level: CPU, Memory...
- Aggragated level metrics: perfromance of database tier..
- business metrics: daily active users...
-
Automation tools
- continuous integration
- autmating build, test and deploy process..
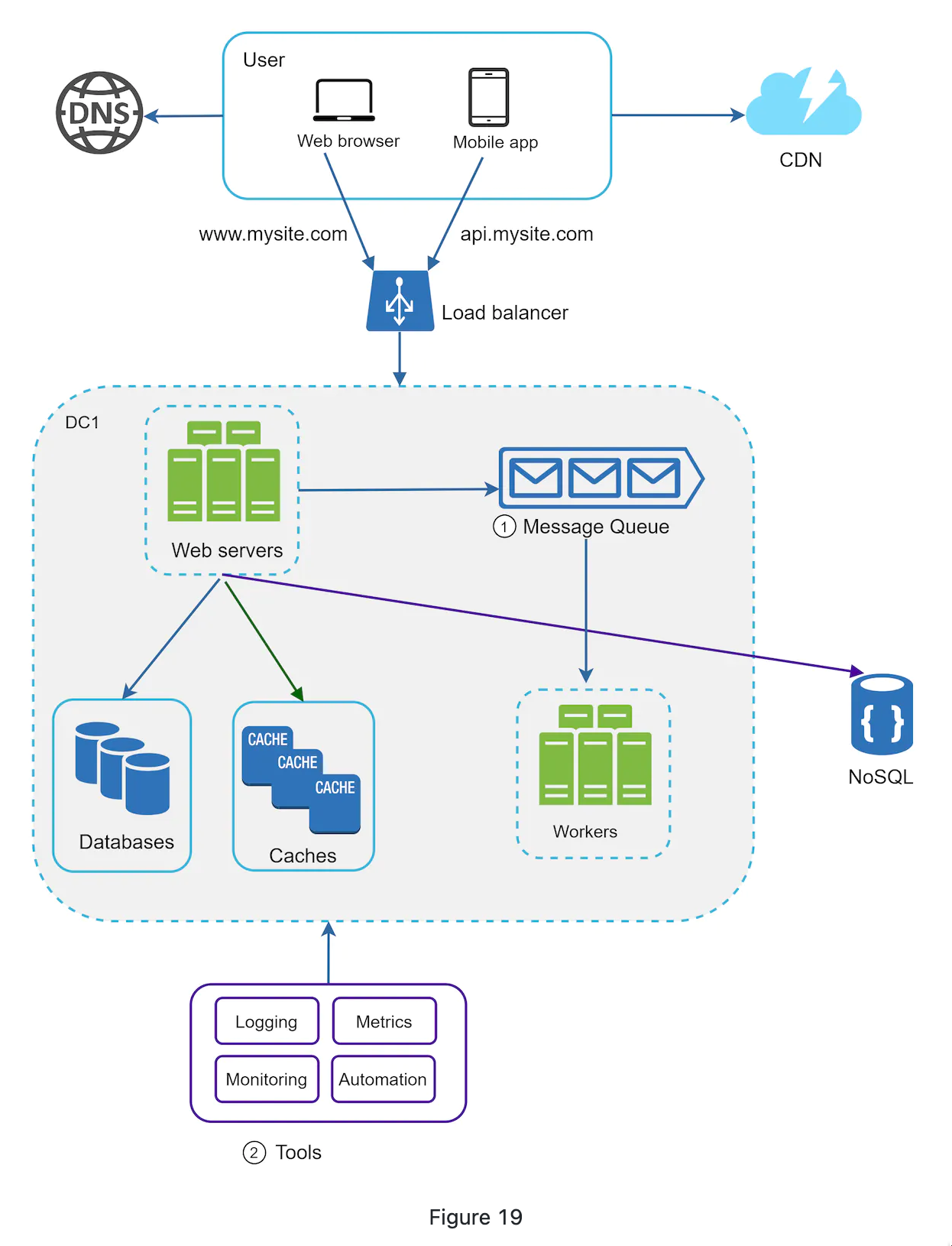
As the data grows, you should also scale the data tier.
Database scaling
-
vertical scaling: more powerful server
-
Not unlimited
-
single point failuer
-
high cost
-
-
horizontal scaling: Sharding seperated large databases into smaller, more easily managed parts -- shards.
-
Sharding key(partition key) consists one or more columns that determine how data is distributed.
-
Cretiria for choosing a sharding key: evenly distributed to servers.
-
Challenges
- Rehashing
- Why: one server takes too much due to uneven distribution; or one server is full
- Consistent hashing
- Celebrity problem
- hotspot key problem.
- To address this issue: allocate partition for hotspot( dedicated)
- Join and de-normalization
- It's hard for tables to join in different partitions.
- Rehashing
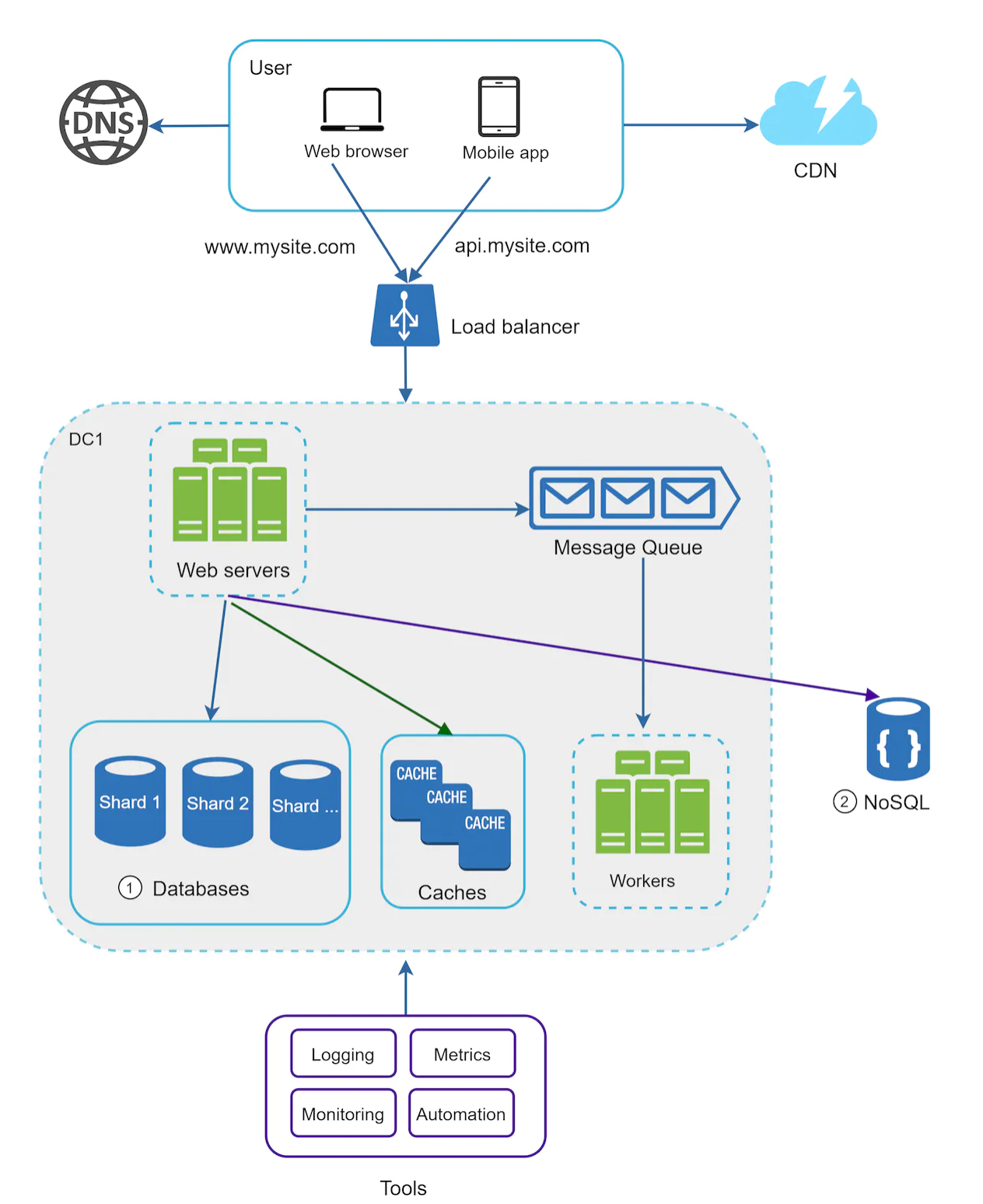
Millions of users and beyond
- scaling system is an iterative process.
- summary
- Keep web tier stateless
- Build redundancy at every tier
- Cache data as much as you can
- Support multiple data centers
- Host static assets in CDN
- Scale your data tier by sharding
- Split tiers into individual services
- Monitor your system and use automation tools