System Design Case Study 6 - Design A Web Crawler
- A crawler is used for many purpose:
- Search engine index
- Web archiving: collect information from the web to preserve data for future use;
- Web mining: Discover useful knowledge from the internet.
- Web monitoring: monitor copyright and trademark infringements over the internet.
1. Understand the requirements/problem and establish design scope
- What is the crawler used for(or what content is it crawling from the internet)? -> search engine index
- how many pages -> 1 billion
- What contents are included? -> html only
- Single server or distributed?
- How long would be the service run? -> 5 years
- how to handle duplicates contents from page? -> ignore
- What is the data volume of scraping? This depends the storage size.
- Public service or private /internal use? Can tolerate some availability?
- Handle The anti-crawler service
10. The function should be simple:
Give a set of urls, download all the webpages addressed by the url
Extract urls from the web pages
Add new URLs to the lists of urls to be downloaded, repeat 1,2,3
11. Besides funcationalities, these characteristics are also need to be considered:
Scalability: The web is large, should utilize paralization
Robustness. Handle edges cases: bad HTML, unresponsive servers, crashes , malicious links, etc.
Politness: should not make too many requests to a site,
Extensibility: if we want to support new content, we do not need to redesign the whole system. Minimal the change
Back of the envelope estimation
- 1 billion page are downloaded every month
- So the QPS would be = 1 billion / 30 days/24h/3600s ~= 386 query/sec
- Assume each page is 500K.
- The storage would be 1 billion*500KB = 5*10^11 KB = 5*10^8 MB=5*10^5 GB=500 TB
- The data is stored 5 years, it would require 500TB * 12 months * 5 years = 30 PB
2. Propose high level design and get buy in
- We have a initial url list to craw
- The server send requests to the urls sites
- Validate valid html contest , The server parse the response and added new urls to the list to be requested; saver save the contents to database,
- The urls list was saved to a in memory cache like Redis as a List(queue)
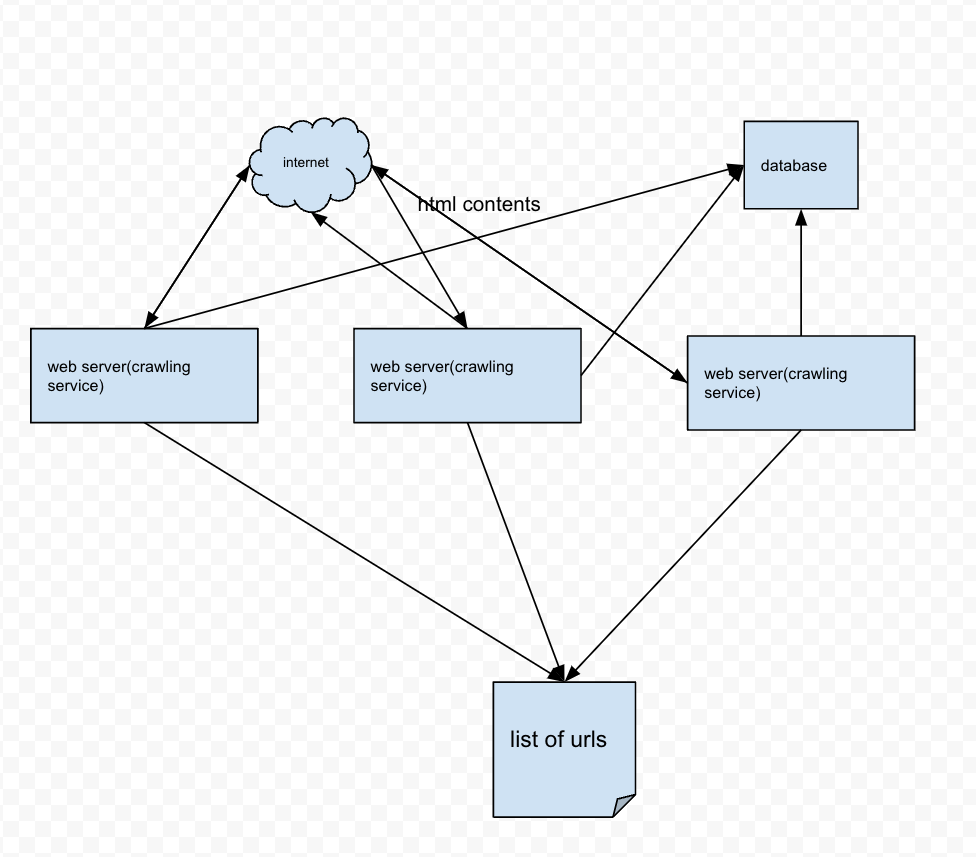
- seed urls
- How to choose ? A school content-> index page
- Entire web -> by country or by topic
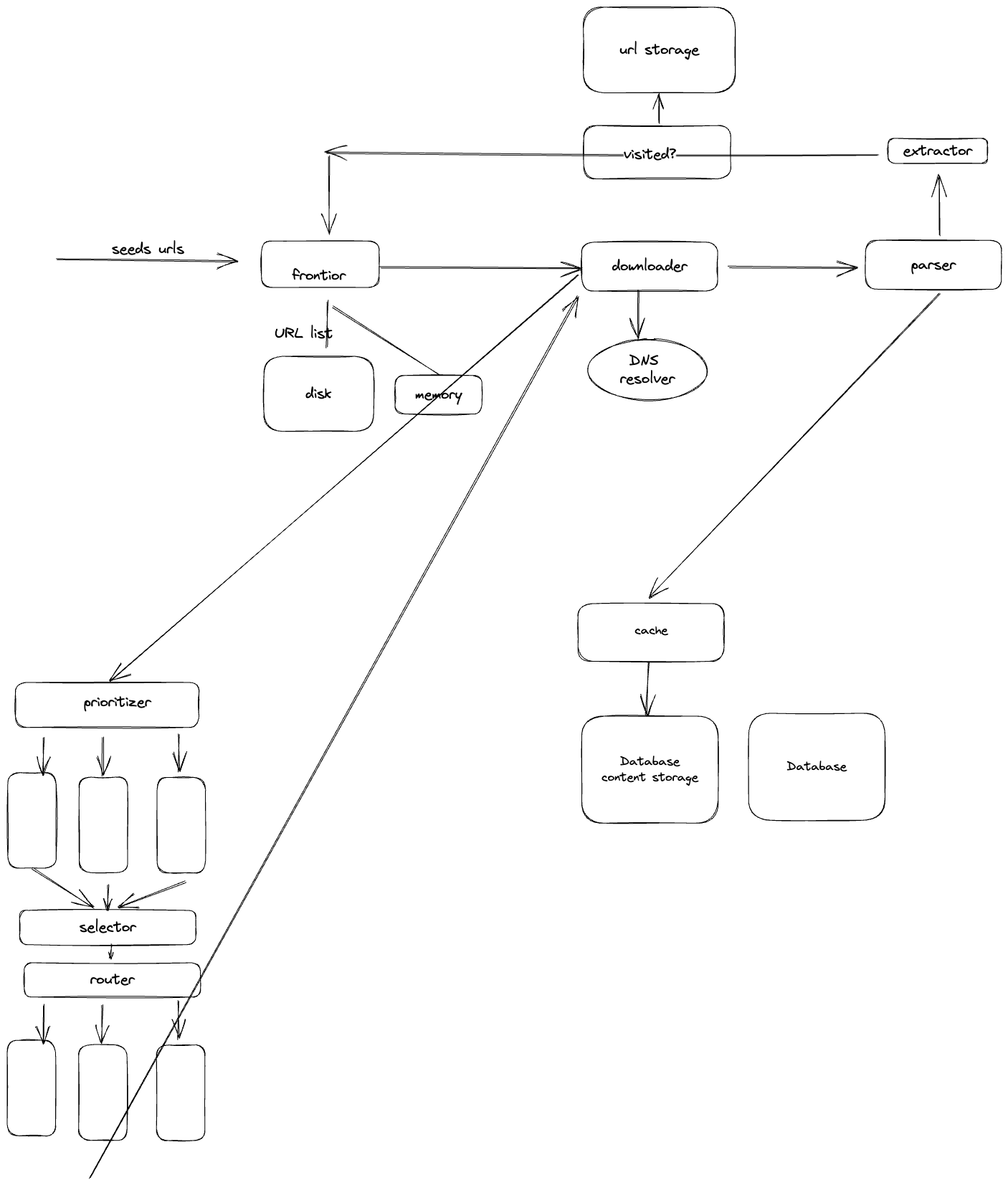
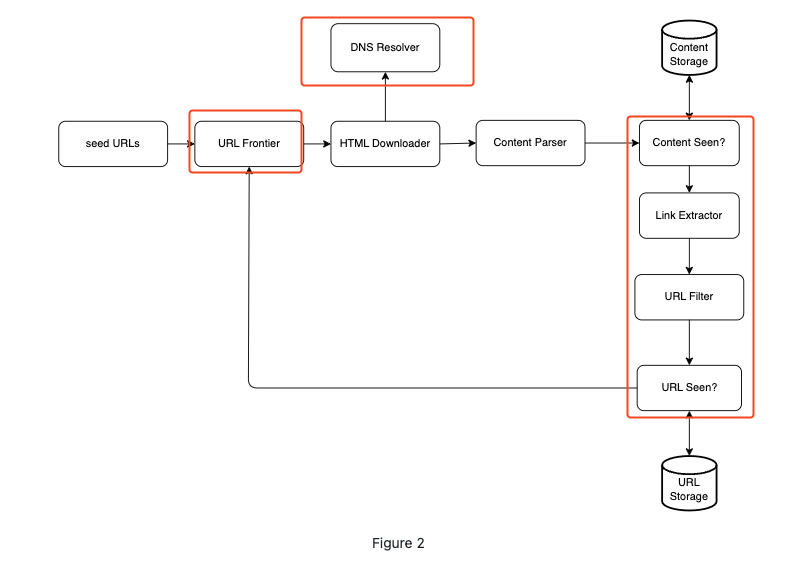
- URL frontier : The component that stores the urls to be downloaded
- URL Downloader
- DNS resolver? Why we need to resolve to DNS?
- Parser
- Content seen? -> to illuminate the repeat content
- Content storage
- URL extractor(maybe could combine with parser)
- URL filter: filter out certain content types, error links...
- URL seen
- URL storage
3. Design deep dive
we will discuss the most important building components and techniques in depth:
- Depth-first search (DFS) vs Breadth-first search (BFS)
- URL frontier
- HTML Downloader
- Robustness
- Extensibility
- Detect and avoid problematic content
DFS vs BFS
-
DFS is not good because the depth may be very deep
-
BFS is commonly used and implemented by queue.
-
The problem is that the url we get using BFS, most of them are from same host, which will cause "impoliteness"(request same host multiple time in short period of time)

-
Another problem is that, normal BFS doesn't take priority into account when traveling. (Some pages are more important)
URL frontier
The frontier (a data structure to save the urls to be downloaded) can help address the politeness problem, priority problem and freshness.
Politeness
- By adding a delay between to download tasks.
- By implement a mapping from hostname to a download thread. Each thread has a separate FIFO queue and only download URLs from that queue.

- Queue router: It ensures that each queue (b1, b2, … bn) only contains URLs from the same host.
- Mapping table: It maps each host to a queue.
| Host | Queue |
|---|---|
| wikipedia.com | b1 |
| apple.com | b2 |
| ... | ... |
| nike.com | bn |
- FIFO queues b1, b2 to bn: Each queue contains URLs from the same host.
- Queue selector: Each worker thread is mapped to a FIFO queue, and it only downloads URLs from that queue. The queue selection logic is done by the Queue selector.
- Worker thread 1 to N. A worker thread downloads web pages one by one from the same host. A delay can be added between two download tasks.
Priority
- Web paged can be prioritized by traffic, update frequency, etc.

freshness
- Web pages are being added, updated and deleted. Re-crawl to keep our data refresh.
- Executed by strategy
- Update frequency
- Important pages
Storage from URL frontier
- In real world there could be millions of frontiers, keep things in memory is not feasable
- The majority are stored on disk, to reduce the cost, maintain a buffer in memory and periodically write to disk.
HTML downloader
- Robots.txt, called Robots Exclusion Protocol, is a standard used by websites to communicate with crawlers. It specifies what pages crawlers are allowed to download. Before attempting to crawl a web site, a crawler should check its corresponding robots.txt first and follow its rules.
- Download from host first to avoid repeat download
Performance optimization
-
Distributed crawl

-
Cache DNS resolver
- This may be a bottleneck due to the synchronous nature of many DNS interface.
- We keep a mapping cache and updated it using a cron job.
-
Locality
Distribute crawl servers geographically. When crawl servers are closer to website hosts, crawlers experience faster download time.
-
Short timeout
Some web servers respond slowly or may not respond at all. To avoid long wait time, a maximal wait time is specified.
Robustness
- Consistent hashing to keep distribute the load to different downloaders.
- Save crawl states and data: To guard against failures, crawl states and data are written to a storage system. A disrupted crawl can be restarted easily by loading saved states and data.
- Exception handling
Extensibility
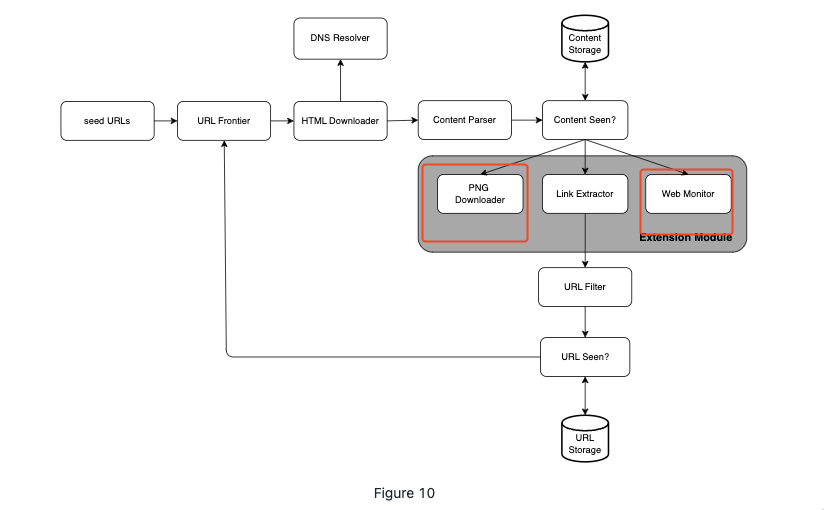
Detect and avoid problematic content
- Redundant content : use hash or checksums
- Spider traps: A spider trap is a web page that causes a crawler in an infinite loop.
- Define max length -> not very good
- Manually identify unusual long urls
- Data noise : no value data
4. Wrap up
- Server-side rendering: Numerous websites use scripts like JavaScript, AJAX, etc to generate links on the fly. If we download and parse web pages directly, we will not be able to retrieve dynamically generated links. To solve this problem, we perform server-side rendering (also called dynamic rendering) first before parsing a page.
- Filter out unwanted pages
- Database replication and sharding
- ...